The Invisible Gorilla Effect in Out-of-distribution Detection for Deep Neural Networks
Harry Anthony, Ziyun Liang, Hermione Warr & Konstantinos Kamnitsas
Invisible Gorilla Experiment
There is a famous psychology experiment in which participants are asked to count basketball passes made by players wearing white shirts. Many participants become so focused on counting basketball passes that they fail to notice a person in a gorilla suit walking through the scene. This well-known experiment, conducted by Daniel Simons and Christopher Chabris, demonstrates a cognitive bias called inattentional blindness, where humans can miss unexpected stimuli when their attention is focused elsewhere. Studies have shown that unexpected objects are more likely to be noticed when they resemble the target we are already looking for. For example, the study found that the gorilla costume was easier to notice when participants were paying attention to the players in black shirts, because the gorilla visually resembled what the participants were already focused on.
Our recent research suggests that AI systems can behave in a similar way.

AI Safety Checks
AI systems have shown impressive performance in understanding images, which has motivated their use in high-risk applications such as diagnosing medical images. In these settings, AI could assist practitioners who often work under intense pressure. However, a common reliability issue is that AI systems often don’t perform well at diagnosing images when they look different from the images they were trained with. Even small unseen artefacts in an image can have a big impact on how reliable the AI predictions are.
To address this problem, researchers have developed AI safety tools known as out-of-distribution (OOD) detection methods. These methods aim to identify when an image differs from the training data. When such images are detected, the system can flag the prediction as potentially unreliable, helping to improve trust in the model’s predictions.
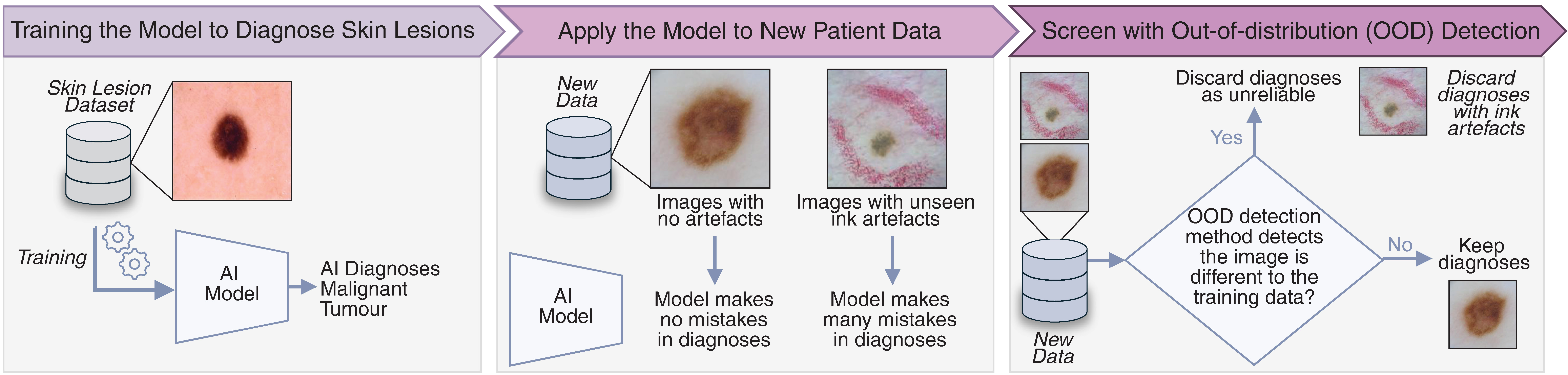
However, the performance of these safety tools is inconsistent. They can sometimes falsely flag correct diagnoses, or fail to detect artefacts that cause the model to make mistakes. Despite this, there has been relatively little research into why their performance varies so widely.
To this end, our research identified a new bias in these AI safety tools.
Invisible Gorilla Effect: A Hidden Bias in AI Safety Checks
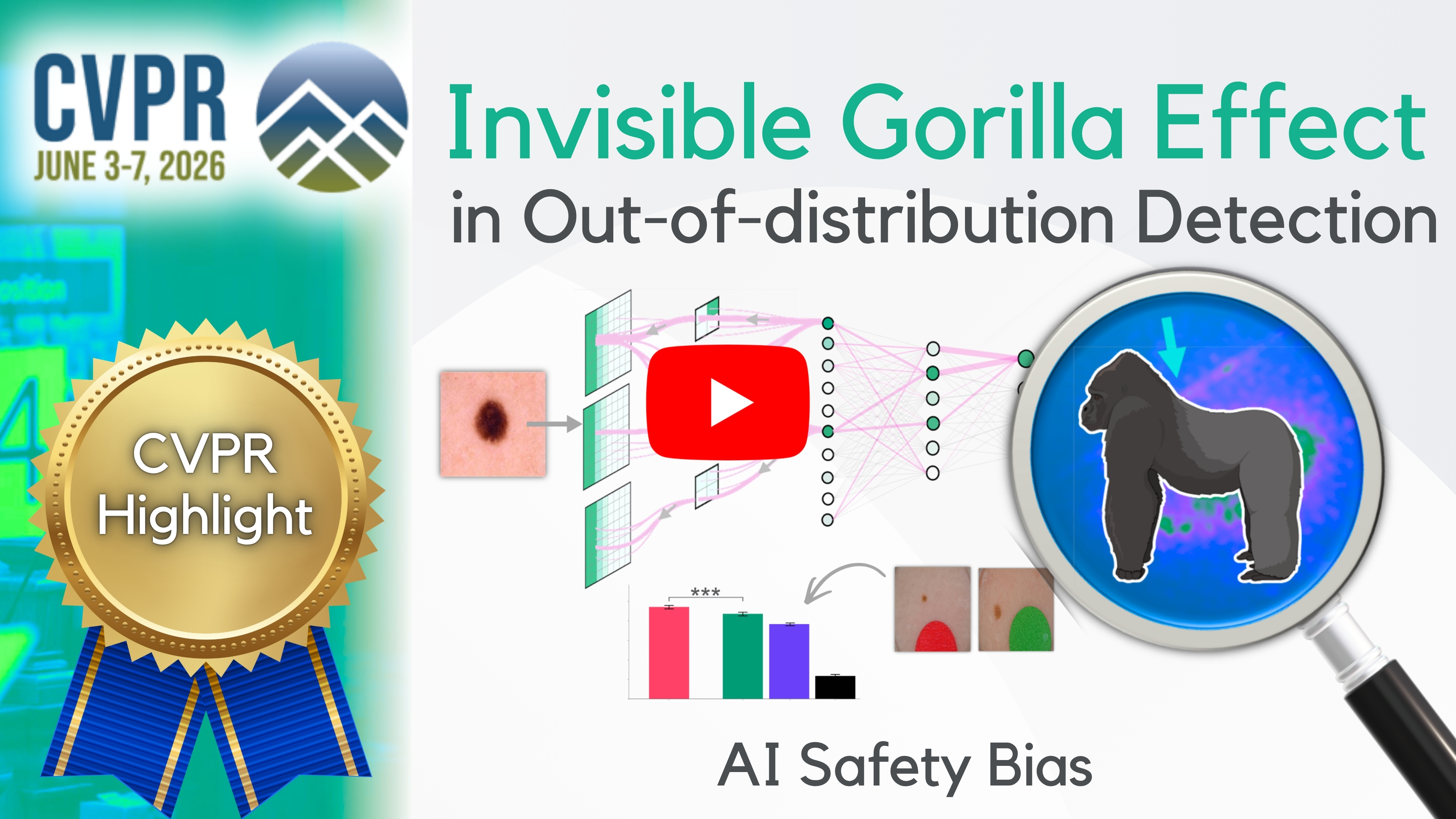
Consider an AI system trained to identify malignant skin lesions in images of patients’ skin. During training, the AI model learns to pay attention to the red-coloured lesion, because that is where the useful medical information is. It also learns to mostly ignore the surrounding background, which usually does not help with the diagnosis.
Now consider showing the AI system a new skin lesion image that contains something it has never seen before, such as an ink mark on the skin. In theory, an AI safety check should notice that this image is unusual and warn us that the diagnosis may not be reliable.
But we found something surprising. The AI safety tool was much better at spotting unexpected ink artefacts when they were a similar colour to the lesion the AI was already focusing on. For example, red ink marks were much easier to detect than green, purple, or black ones because they were visually similar to the red-coloured skin lesion.
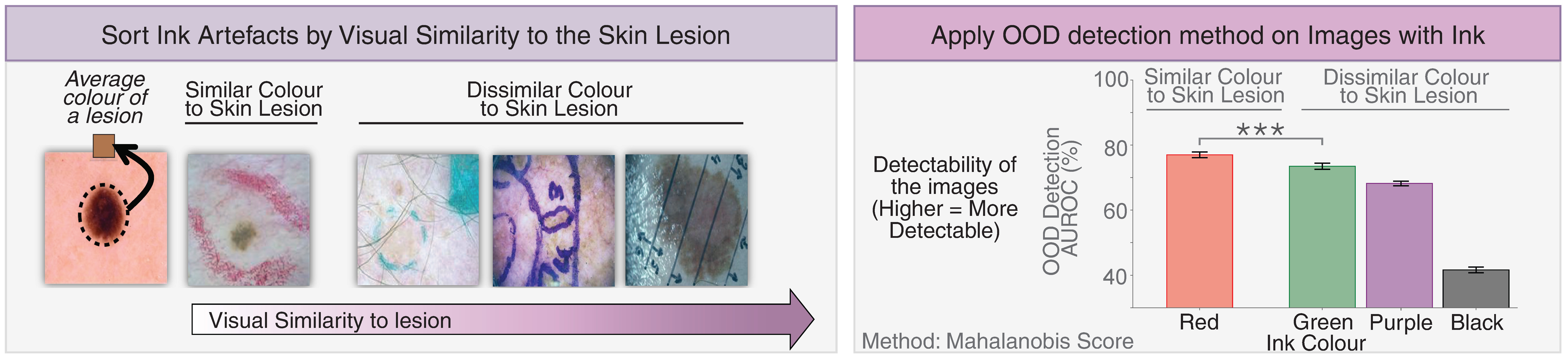
We saw the same pattern across other medical imaging tasks, including chest X-rays and dermatology, and industrial equipment inspection tasks. Overall, these safety tools were better at detecting unexpected artefacts when those artefacts resembled the part of the image the AI model was already paying attention to. When the artefacts looked very different, the tools were more likely to miss them. This behaviour closely resembles the invisible gorilla experiment: unexpected objects are more likely to be noticed when they resemble the object we are already focusing on. For this reason, we call this bias the Invisible Gorilla Effect.
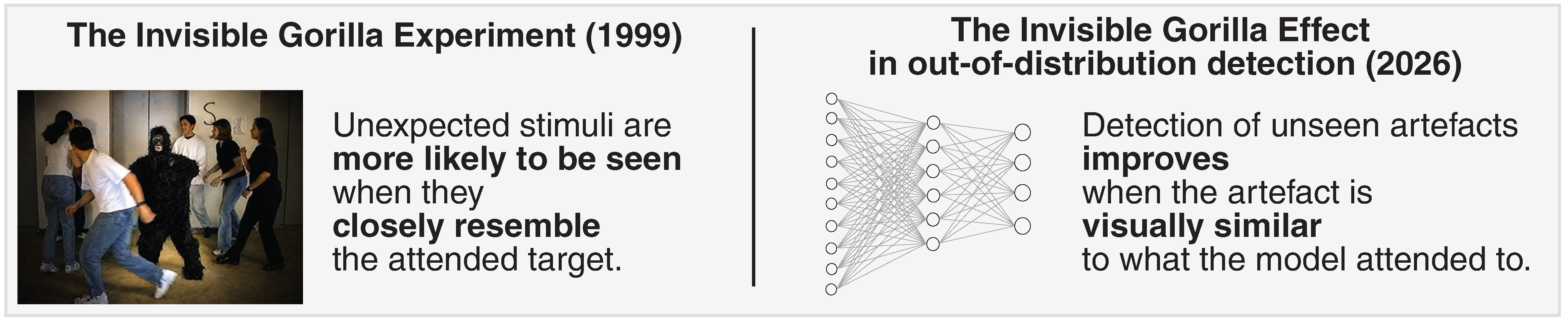
This finding challenges a common assumption in the AI safety community. Typically, researchers assume that the more different an image is from the training data, the easier it should be to detect. Our results suggest the opposite may sometimes be true, suggesting what the model attends to has a major impact on AI safety tools. Better understanding these biases is important for designing safer and more reliable AI systems.
This research was recently accepted as a Highlight at CVPR 2026, one of the largest conferences in AI research. In the paper, we investigate how the Invisible Gorilla Effect impacts a wide range of out-of-distribution detection methods, explore why the phenomenon occurs and discuss how future AI safety tools could be designed to be more robust.
| 📄 Paper | </> Code |